在很多项目需求中会存在A仓库需要使用B仓库的情况,此时可以将模块B添加为A的子模块,执行在A的目录下执行如下命令
git submodule add <url> <path>即可将模块B添加为A的子模块,如果在其他设备想拉取仓库A需要执行
git clone -b <branch> --recurse-submodules <repo_url>这条命令主要做了这几件事
- 从远端clone主仓库
- 切到branch分支
- 初始化所有子模块
- 拉取所有子模块
- 把所有子模块牵出到父模块指定commit
此时即可按照主仓库的branch分支记录的每一个子模块的特定commit进行构建等操作
问题在哪?
此时如果需要对子模块进行开发我们可能会到子模块目录下进行查看现在处于哪个分支,会发生如下情况
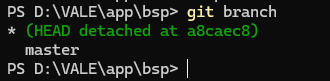
有好多人一看,咦?我明明记得父模块的这个子模块是引入的xxxx分支啊,怎么会有游离的这种情况?
更糟糕的是,伴随着对这个游离HEAD进行更改是无法直接提交推送的,有很多人会直接 focus pull直接强制推送,千万不要这么做。这么做属于是一种凭空捏造分支,强推会重写分支历史,会让别人本地/父仓库记录的子模块 commit 失效,轻则冲突,重则整个工程不可复现。
原理分析
这事还得从git的原理说起,git中一共存在三种核心对象
- commit:一次快照(不可变,有 hash)
- branch:一个“指针”,名字 → 指向某个 commit,相当于给commit起了个别名
- HEAD:你当前所处的位置,通常指向某个branch
重点来了,由上面的核心对象可知,从branch可以推出指向某个commit,由HEAD通常情况下亦可推出指向某个branch,这个时候呈现出的HEAD是这样的
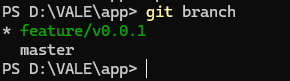
可以看到HEAD是指向了feature/v0.0.1这个分支,git会根据这个branch推导到某次commit,这个commit就是分支当前的文件快照。
但,当子模块来了,就不一样了,子模块实际上是在父模块的快照里保存了指向子模块的commit,问题是,如上方所述,子模块实际上是commit,而HEAD又是你当前所处的位置,通常指向某个branch,但他也可能指向某次commit,此时的HEAD就代表了一个commit,又由git的核心对象可推,由branch可推出指向某次commit,但是从commit却是推不出是哪个branch,所以看到的

实际上是正常行为,因为commit只能代表快照,而无法代表某个分支,而子模块使用的恰好就是这种快照。
解决措施
如果只是使用子模块的文件,比如进行构建编译,完全可以不必理会,但如果需要对子模块进行修改的话就需要到子模块下牵出一个已经存在的分支或者新建分支进行开发操作,如下图
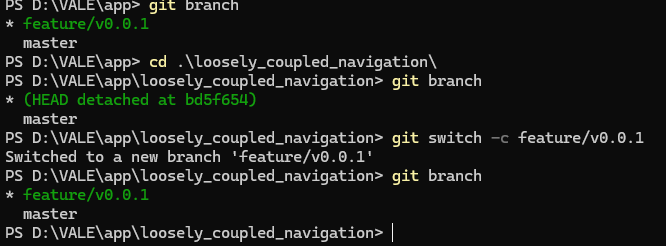
先cd到子模块的目录下,然后牵出子模块的分支,再进行开发,如此可解。

参与讨论